На прошлой неделе состоялся успешный эксперимент по запуску нового решения для download-сервиса. Один достаточно скромный сервер (2 x Intel Xeon E5620, 64 GB RAM) под управлением Java-приложения собственной разработки принял на себя нагрузку восьми Tomcat’ов, обслуживая более 70 тысяч HTTP-запросов в секунду общей пропускной способностью 3000 Mb/s. Таким образом, весь трафик Одноклассников, связанный с пользовательскими смайликами, обрабатывался одним сервером.
Вполне естественно, что высокие нагрузки требовали нестандартных решений. В цикле статей о разработке высоконагруженного сервера на Java я расскажу о проблемах, с которыми нам пришлось столкнуться, и о том, как мы их преодолели. Сегодня речь пойдет о кешировании изображений вне Java Heap и об использовании Shared Memory в Java.
Кеширование
Поскольку тянуть изображения на каждый запрос из хранилища — не вариант, а о хранении картинок на диске не может быть и речи (дисковая очередь станет узким местом сервера гораздо раньше), необходимо иметь быстрый кеш в памяти приложения.
Не стоит запускать Жуткий файл Revuxor в Майнкрафт!
- 64-bit keys, byte array values: идентификатор изображения — целое число типа long, а данные — картинка в формате PNG, GIF или JPG со средним размером 4 KB;
- In-process, in-memory: для максимальной скорости доступа все данные — в памяти процесса;
- RAM utilization: под кеш выделяется вся доступная оперативная память;
- Off-heap: 50 GB данных разместить в Java Heap было бы проблематично;
- LRU или FIFO: устаревшие ключи могут вытесняться более новыми;
- Concurrency: одновременное использование кеша в сотне потоков;
- Persistence: приложение может быть перезапущено с сохранением уже закешированных данных.
Shared Memory
В Linux объекты Shared Memory реализованы посредством специальной файловой системы, монтируемой к /dev/shm . Так, например, POSIX функция shm_open(«name», . ) эквивалентна системному вызову open(«/dev/shm/name», . ) . Таким образом, в Java мы можем работать с разделяемой памятью Linux как с обычными файлами. Следующий фрагмент кода откроет объект разделяемой памяти с именем image-cache размером 1 GB. Если объекта с таким именем не существует, будет создан новый. Важно, что после завершения приложения объект останется в памяти и будет доступен при следующем запуске.
RandomAccessFile f = new RandomAccessFile(«/dev/shm/image-cache», «rw»); f.setLength(1024*1024*1024L);
Теперь созданный объект-файл надо отобразить в адресное пространство процесса и получить адрес этого участка памяти.
Способ 1. Легальный, но неполноценный
Воспользуемся Java NIO API:
RandomAccessFile f = . MappedByteBuffer buffer = f.getChannel().map(FileChannel.MapMode.READ_WRITE, 0, f.length());
Самый главный недостаток этого метода заключается в том, что нельзя отображать файлы размером более 2 GB, что и описано в Javadoc к методу map: The size of the region to be mapped; must be non-negative and no greater than Integer.MAX_VALUE.
Работать с полученным участком памяти можно либо стандартными методами ByteBuffer’а, либо напрямую через Unsafe, вытащив адрес памяти с помощью Reflection:
public static long getByteBufferAddress(ByteBuffer buffer) throws Exception
Публично доступного метода unmap у такого MappedByteBuffer’а нет, однако есть полу-легальный способ освободить память без вызова GC:
((sun.nio.ch.DirectBuffer) buffer).cleaner().clean();
Способ 2. Полностью на Java, но с использованием «тайных знаний»
В Oracle JDK есть класс sun.nio.ch.FileChannelImpl с приватными методами map0 и unmap0 , которые лишены ограничения в 2 GB. map0 возвращает непосредственно адрес «замапленного» участка, что для нас даже удобнее, если мы используем Unsafe.
Method map0 = FileChannelImpl.class.getDeclaredMethod( «map0», int.class, long.class, long.class); map0.setAccessible(true); long addr = (Long) map0.invoke(f.getChannel(), 1, 0L, f.length()); Method unmap0 = FileChannelImpl.class.getDeclaredMethod( «unmap0», long.class, long.class); unmap0.setAccessible(true); unmap0.invoke(null, addr, length);
Такой механизм будет работать как в Linux, так и под Windows. Единственный его недостаток — отсутствие возможности выбора конкретного адреса, куда будет «замаплен» файл.
Необходимость в этом может возникнуть, если в кеше присутствуют абсолютные ссылки на адреса памяти внутри этого же кеша: такие ссылки станут невалидными, если отобразить файл по другому адресу. Выхода два: либо хранить относительные ссылки в виде смещения относительно начала файла, либо прибегнуть к вызову нативного кода через JNI или JNA. Системные вызовы mmap в Linux и MapViewOfFileEx в Windows позволяют задать предпочитаемый адрес, куда «замапить» файл.
Алгоритм кеширования
Ключевым для производительности кеша, да и download-сервера в целом, является алгоритм поиска в кеше, т.е. метод get . Метод put в нашем сценарии вызывается значительно реже, но тоже не должен быть слишком медленным. Хочу представить наше решение для быстрого потокобезопасного FIFO кеша в непрерывной области памяти фиксированного размера.
Вся память разделяется на сегменты одинакового размера — корзины хеш-таблицы, по которым равномерно распределяются ключи. В самом простом виде
Segment s = segments[key % segments.length];
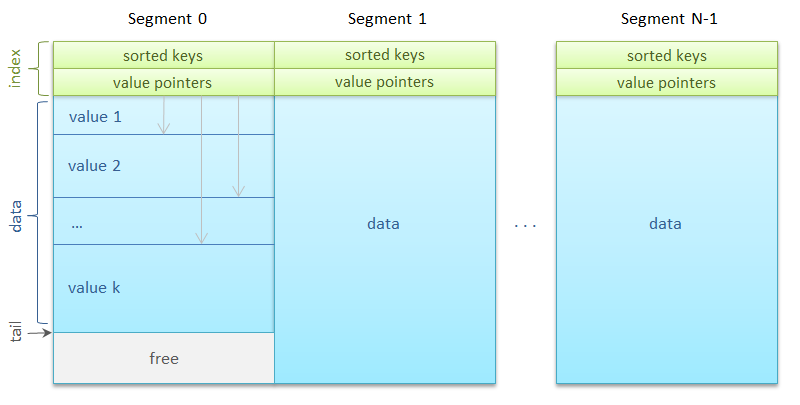
Сегментов может быть много — несколько тысяч. Каждому из них сопоставляется ReadWriteLock . Одновременно с сегментом может работать либо неограниченное количество читателей, либо только один писатель.
Интересная деталь: использование стандартных ReentrantReadWriteLock’ов привело к потере 2 GB в Java Heap. Как оказалось, в JDK 6 существует ошибка, приводящая к чрезмерному потреблению памяти таблицами ThreadLocal в реализации ReentrantReadWriteLock . Хотя в JDK 7 ошибка уже исправлена, в нашем случае мы заменили прожорливый Lock на Semaphore . Кстати, вот вам и маленькое упражнение:
как реализовать ReadWriteLock при помощи Semaphore?
Итак, сегмент. Он состоит из области индекса и области данных. Индекс представляет собой упорядоченный массив из 256 ключей, сразу за которым идет такой же длины массив из 256 ссылок на значения. Ссылка задает смещение внутри сегмента на начало блока данных и длину этого блока в байтах.

Блоки данных, то есть, собственно сами изображения, выравнены по восьмибайтовой границе для оптимального копирования. Сегмент также хранит количество ключей в нем и адрес следующего блока данных для метода put . Новые блоки записываются друг за другом по принципу циклического буфера. Как только место в сегменте кончается, происходит запись с начала сегмента поверх более ранних данных.
- по хешу ключа вычисляется сегмент, в котором будет производиться поиск;
- в области индекса бинарным поиском ищется ключ;
- если ключ найден, из массива ссылок достается смещение, по которому располагаются данные.
- по хешу ключа вычисляется сегмент;
- считывается адрес очередного блока данных и вычисляется адрес следующего блока путём прибавления размера записываемого объекта с учетом выравнивания;
- если сегмент заполнен, линейным поиском по массиву ссылок находятся и удаляются из индекса ключи, чьи данные будут перезаписаны очередным блоком;
- значение, представленное байтовым массивом, копируется в область данных;
- бинарным поиском находится место в индексе, куда вставляется новый ключ.
Скорость работы
- put: запись 1 млн. значений размером от 0 до 8 KB каждое;
- get: поиск по ключу 1 млн. значений;
- 90% get + 10% put: комбинирование get/put в отношении, приближенном к практическому сценарию использования кеша.

Впрочем, стоит отметить, что описанный алгоритм, будучи предназначенным для решения задачи кеширования изображений, не охватывает многих других сценариев. Например, операции remove и replace , хотя и могут быть легко реализованы, не будут освобождать память, занятую прежними значениями.
Где посмотреть?
Исходные тексты алгоритма кеширования с использованием Shared Memory на github:
https://github.com/odnoklassniki/shared-memory-cache
Где послушать?
На встрече JUG.RU в Санкт-Петербурге, которая состоится 25 июля 2012 г., apangin поделится опытом разработки высоконагруженного сервера на Java, расскажет о характерных проблемах и нетрадиционных приемах.
Что дальше?
В следующих статьях я расскажу, как написать RPC-сервер, обрабатывающий десятки тысяч запросов в секунду, а также поведаю об альтернативном методе сериализации, в разы превосходящем стандартные механизмы Java по производительности и объему трафика. Оставайтесь с нами!
- Одноклассники corporate blog
- High performance
- Java
Источник: habr.com
MineCraft and Off Heap Memory

I used the following test for starting minecraft server from a seed from scratch which is a particularly expensive operation for the server.
- Preset the level-seed=114 in server.properties
- Delete the world* directories
- Start the server with these options to see what the GC is doing -Xloggc:gc.log
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps -XX:+PrintTenuringDistribution -Xmx6g - Connect with one client
- Perform /worldgen village
- Perform /save-all
- Exit.
To analyse the logs I am using jClarity’s Censum.
Standard MineCraft
There is two particularly expensive things it does
- It caches block stage in many byte[]s
- It attempts to cache int[] used for processing without limit.
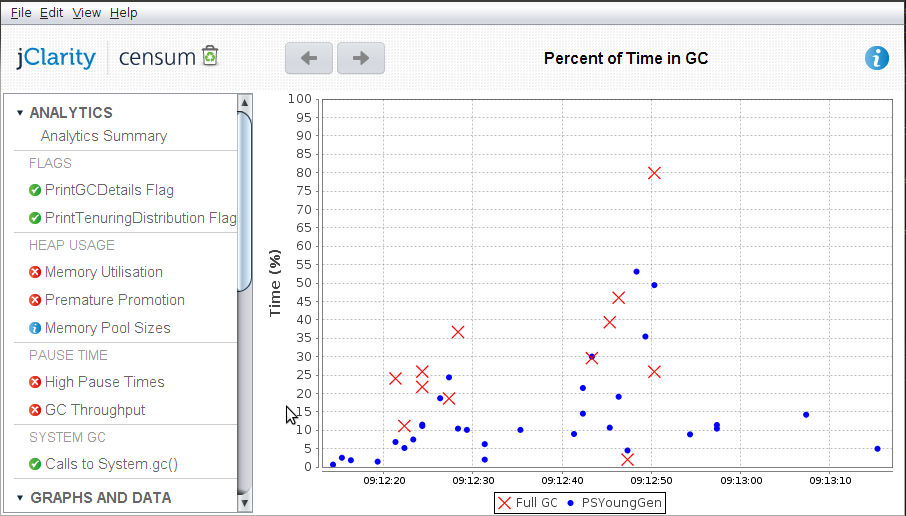
The high pause times are partly due to having to manage the large objects.
Off heap MineCraft
Two changes were made to address this
- Use off heap ByteBuffer for long term caching. Unsafe would be more efficient but not as portable.
- Put a cap on the number of int[] cached.
A Censum report for the same test looks like this

There is still some premature promotion i.e. further improvements can be made but you can see that the application is spending.
Conclusion
Using off heap memory can help you tame you GC pause times, especially if the bulk of your data is in simple data structures which can be easily abstracted. Doing so can also help reveal other simple optimisations you can do to improve the consistency of your performance.
Источник: laptrinhx.com
Вспомнить все: 6 сегментов памяти Apache Spark и параметры их конфигурирования

В этой статье продолжим говорить про обучение разработчиков Apache Spark и рассмотрим, какие сегменты памяти есть в этом Big Data фреймворке и как с ними работать наиболее эффективно. Читайте далее, почему процессы PySpark и SparkR потребляют внешнюю память, чем пользовательская память кучи JVM отличается от памяти хранилища и какие конфигурации нужно настроить, чтобы ускорить распределенные вычисления и предотвратить возможные утечки.
В JVM и не только: виды памяти Apache Spark
Напомним, при том, что Apache Spark поддерживает Java, R и Python, основным языком реализации самого фреймворка является Scala. Поэтому все операции выполняются внутри JVM, даже если пользовательский код написан на Python или R. Среда выполнения фреймворка разделяет пространство кучи (Heap) JVM в драйвере и исполнителях на 4 разные части [1]:
- память хранилища (Storage Memory), зарезервированная для кэшированных данных;
- память выполнения (Execution Memory), используемая структурами данных во время shuffle-операций, при которых данные перемешиваются – т.е. соединение, группировка и агрегирование;
- пользовательская память (User Memory) для хранения структур данных, созданных и управляемых пользовательским кодом;
- зарезервированная память (Reserved Memory) для внутренних целей фреймворка.
Кроме JVM Heap, есть еще два сегмента памяти, к которым обращается Spark:
- память вне кучи (Off-Heap Memory)– сегмент за пределами JVM, который иногда используется виртуальной машиной Java, например, для метода intern(), гарантирующего что все строки с одинаковым содержимым, совместно используют одну и ту же память. Память вне кучи также может использоваться для хранения сериализованных датафреймов и RDD. О том, как сохранить датафрейм в память исполнителя вне кучи, читайте в нашей отдельной статье.
- внешняя память процесса (External Process Memory), которую используют программы на PySpark и SparkR в рамках процессов Python и R вне JVM.
Какие параметры конфигурации стоит настроить, чтобы использовать каждый вид памяти наиболее эффективно, мы рассмотрим далее.
2 самых важных параметра для памяти хранилища
Раздел Memory Management в официальной документации Спарк включает целых 10 различных конфигураций для настройки управления памятью фреймворка. Из них к памяти хранилища относятся следующие [2]:
- memory.fraction – сегмент от 300 МБ JVM-кучи для выполнения и хранения данных. По умолчанию его значение равно 0,6 – чем оно меньше, тем чаще происходит утечка и вытеснение кэшированных данных. Эта конфигурация позволяет выделить память для внутренних метаданных и структур пользовательских данных, а также приблизительно оценить размер разреженных необычно больших записей.
- memory.storageFraction – часть области spark.memory.fraction, объем памяти хранения, невосприимчивый к вытеснению, по умолчанию равный 0,5. Чем больше это значение, тем меньше оперативной памяти доступно для выполнения, и задачи чаще сохраняются на диск.
Таким образом, оба параметра устанавливают объем пространства JVM, который будет использоваться в качестве памяти для хранения и кэширования данных). Но spark.memory.fraction определяет общий объем памяти, выделенной как для перемешивания, так и для хранения данных. А объем памяти, защищенной от вытеснения, определяется параметром spark.memory.storageFraction.

Исполнители и память вне кучи
При том, что большинство операций в Спарк происходит внутри JVM и использует ее кучу для своей памяти, каждый исполнитель может также иногда обращаться к внешнему пространству за пределами виртуальной машины Java через API-интерфейсы sun.misc.Unsafe. Эта память вне кучи находится за пределами области сборки мусора, поэтому предоставляет разработчику приложения более точный контроль над памятью. В частности, фреймворк использует эту память вне кучи для более эффективной работы с памятью за счет метода String.intern() и накладных расходов JVM. Также off-heap memory нужна фреймворку для хранения данных в рамках проекта Tungsten – компонента Spark SQL, который повышает эффективность операций обработки данных, работая непосредственно на уровне байтов.
Core Spark — основы для разработчиков
Код курса
CORS
Ближайшая дата курса
18 апреля, 2023
Длительность обучения
16 ак.часов
Стоимость обучения
44 000 руб.
Общая память вне кучи для исполнителя Спарк контролируется конфигурацией spark.executor.memoryOverhead, по умолчанию равной 10% памяти исполнителя при минимальном размере 384 МБ. Даже если пользователь явно не задает этот параметр, фреймворк сам выделит 10% памяти исполнителя или 384 МБ, в зависимости от того, что больше для накладных расходов JVM [1].
Этот объем дополнительной памяти, выделяемой для каждого процесса-исполнителя, увеличивается по мере роста размера исполнителя. В настоящее время опция поддерживается в YARN и Kubernetes. Дополнительная память также включает память исполнителя PySpark (если spark.executor.pyspark.memory не настроен специально) и память, используемую другими процессами, не являющимися исполнителями, в том же контейнере [2]. Примерный расчет оптимального количества ресурсов на исполнителя смотрите в нашей новой статье.
Объем памяти вне кучи, используемый фреймворком для хранения фактических датафреймов, определяется параметром spark.memory.offHeap.size. Это дополнительная функция, которую можно включить, установив для spark.memory.offHeap.use значение true. Примечательно, что в предыдущих релизах фреймворка (до версии 3.x) общая память вне кучи, указанная с помощью memoryOverhead, также включала память вне кучи для датафреймов. Версия 3.0 отделяет off-heap от memoryOverhead, поэтому теперь разработчику не нужно волноваться о размерах датфреймов во время установки memoryOverhead исполнителя [1].
Максимальный объем памяти контейнера для запущенного исполнителя равен сумме значений spark.executor.memoryOverhead, spark.executor.memory, spark.memory.offHeap.size и spark.executor.pyspark.memory [2].

Что разработчик Spark-приложений должен знать о памяти Python: особенности PySpark
При выполнении пользовательского кода на PySpark используются участки памяти, заданные в конфигурациях spark.python.worker.memory и spark.executor.pyspark.memory. При работе с Python-кодом в PySpark исполнитель выполняет два отдельных процесса, которые взаимодействуют друг с другом через мост Py4J:
- JVM выполняет часть кода Спарк, связанный с операциями перемешивания, такими как соединение и агрегирование;
- python, который непосредственно выполняет код пользователя.
Параметр spark.python.worker.memory управляет объемом памяти, зарезервированной для каждого процесса worker’а PySpark, за пределами которого он переносится на диск, т.е. этот объем памяти может быть занят объектами, созданными через мост Py4J во время Спарк-операций. Если этот параметр не установлен, его значение по умолчанию равно 512 МБ.
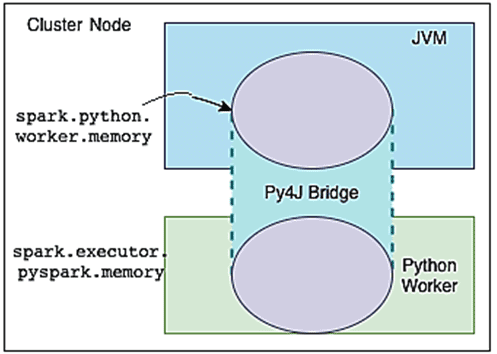
Начиная с версии 2.4, параметр spark.executor.pyspark.memory контролирует фактическую память процесса worker’а Python, устанавливая предел пространства памяти, который он может адресовать, с помощью свойства system.RLIMIT_AS. Если память worker’а Python не установлена через параметр spark.executor.pyspark.memory, этот процесс потенциально может занять всю память узла. А, поскольку эта часть памяти не отслеживается диспетчером ресурсов Спарк-кластера, таким как Hadoop YARN, есть риск перепланирования в узле и смены страниц в памяти. В результате возможно замедление работы всех контейнеров YARN на этом узле. Поэтому следует настраивать оба параметра [1]:
- python.worker.memory, который ограничивает память в JVM для объектов Python;
- executor.pyspark.memory, который ограничивает фактическую память процесса Python.
В заключение отметим, что общая память, запрошенная фреймворком у диспетчера контейнеров, в частности, Hadoop YARN, равна сумме памяти исполнителя, накладных расходов памяти и лимита памяти worker’а, на котором выполняется программа Python [1].

Освойте все тонкости разработки распределенных приложений Apache Spark для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве :
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источник: www.bigdataschool.ru