При запуске нового проекта в области науки о данных первым шагом после получения набора данных в первый раз является его понимание. Мы достигаем этого, выполняя исследовательский анализ данных (EDA). Это включает в себя определение типа данных каждой переменной, распределения целевой переменной, количества различных значений для каждой переменной-предиктора, наличия каких-либо повторяющихся или отсутствующих значений в наборе данных и т. Д.
Если вы когда-либо выполняли EDA для любого набора данных (и я предполагаю, что вы это сделали, когда читаете эту статью), мне не нужно говорить вам, сколько времени может потребоваться этот процесс. И если вы участвовали во многих проектах по науке о данных (будь то на работе или в личных проектах), вы знаете, насколько повторяющимся может быть весь этот процесс. Но с библиотекой с открытым исходным кодом профилирование Pandas больше не должно происходить.
Что такое профилирование панд?
Pandas-profiling — это библиотека с открытым исходным кодом, которая может создавать красивые интерактивные отчеты для любого набора данных с помощью всего одной строчки кода. Звучит интересно? Давайте посмотрим на документацию, чтобы лучше понять, что она делает.
Главные ОШИБКИ при создании сервера! Как создать сервер в майнкрафт?
Pandas-profiling создает отчеты профиля из pandas DataFrame . Функция pandas df.describe() прекрасна, но немного проста для серьезного исследовательского анализа данных. pandas_profiling расширяет фрейм данных pandas с помощью df.profile_report() для быстрого анализа данных.
Для каждого столбца в интерактивном HTML-отчете представлена следующая статистика, если она актуальна для данного типа столбца:
- Вывод типа: определение типов столбцов во фрейме данных.
- Основы: тип, уникальные значения, отсутствующие значения.
- Квантильная статистика, например минимальное значение, Q1, медиана, Q3, максимум, диапазон, межквартильный диапазон.
- Описательная статистика, например среднее значение, режим, стандартное отклонение, сумма, среднее абсолютное отклонение, коэффициент вариации, эксцесс, асимметрия.
- Наиболее частые значения
- Гистограмма
- Корреляции: выделение сильно коррелированных переменных (матрицы Спирмена, Пирсона и Кендалла)
- Матрица отсутствующих значений, количество, тепловая карта и дендрограмма пропущенных значений
- Анализ текста узнайте о категориях (прописные буквы, пробел), скриптах (латиница, кириллица) и блоках (ASCII) текстовых данных.
Теперь, когда мы знаем, что такое профилирование pandas, давайте посмотрим, как его установить и использовать в блокноте Jupyter или в Google Colab в следующем разделе.
Установите Pandas-profiling:
Использование pip
Вы можете очень легко установить pandas-profiling с помощью диспетчера пакетов pip с помощью следующей команды:
pip install pandas-profiling[notebook,html]
В качестве альтернативы вы можете установить последнюю версию прямо из Github:
Использование Conda
Если вы используете conda, вы можете использовать следующую команду для установки
🙅♂️ ОШИБКИ НОВИЧКОВ ПРИ СОЗДАНИИ СЕРВЕРА В МАЙНКРАФТ #2
conda install -c conda-forge pandas-profiling
Установка в Google Colab
Google colab поставляется с предустановленным профилированием Pandas, но, к сожалению, он имеет более старую версию (v1.4). Если вы следите за этой статьей или документацией GitHub, то код не будет работать в Google Colab, если вы не установите последнюю версию библиотеки (v2.6).
Для этого вам необходимо сначала удалить существующую библиотеку и установить последнюю, как показано ниже:
# To uninstall !pip uninstall !pip uninstall pandas_profiling
Теперь для установки нам нужно запустить команду pip install.
!pip install pandas-profiling[notebook,html]
Создавать отчеты:
Теперь, когда мы закончили с предварительными условиями, давайте перейдем к интересной части анализа некоторого набора данных.
Набор данных, который я буду использовать для этого примера, — это набор данных Титаник.
Загрузите библиотеки:
import pandas as pd import pandas_profiling from pandas_profiling import ProfileReport from pandas_profiling.utils.cache import cache_file
Импортировать данные
file = cache_file(«titanic.csv», «https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv») data = pd.read_csv(file)

Создать отчет:
Чтобы создать отчет, запустите в записной книжке следующий код.
profile = ProfileReport(data, title=»Titanic Dataset», html=>, sort=»None»)

Вот и все. С помощью одной строчки кода вы создали подробный отчет о профиле. Теперь посмотрим на результаты, включив отчет в блокнот.
Включить отчет в Блокнот как IFrame
profile.to_notebook_iframe()
Это будет включать интерактивный отчет в виде HTML-окна iframe в записной книжке.
Сохранение отчета
Сохраните отчет как HTML-файл, используя следующий код:
profile.to_file(output_file=»your_report.html»)
Или получите данные в формате JSON, используя:
# As a string json_data = profile.to_json() # As a file profile.to_file(output_file=»your_report.json»)
Результаты, достижения:
Теперь, когда мы знаем, как создавать отчеты с помощью профилирования pandas, давайте посмотрим на результат.
Обзор:


Pandas_profiling создает очень подробный обзор переменных-предикторов, вычисляя общее количество пропущенных ячеек, повторяющихся строк, количество различных значений, пропущенных значений, нулей для переменных-предикторов. Он также отмечает переменные с высокой мощностью или отсутствующими значениями в разделе предупреждений, как вы можете видеть на изображении выше.
Помимо всего этого, он генерирует подробный анализ для каждой переменной. Я пройдусь по некоторым из них в этой статье, чтобы увидеть полный отчет со всеми кодами, найдите ссылку colab в конце статьи.
Распределение классов:

Числовые характеристики:

Для числовых характеристик, помимо подробной статистики, такой как среднее значение, стандартное отклонение, минимум, максимум, межквартильный диапазон (IQR) и т. Д., Он также строит гистограмму, дает список общих и экстремальных значений.
Категориальные особенности:
Подобно числовым признакам, для категориальных признаков он вычисляет общие значения, длину, символы и т. Д.

Взаимодействия:
Одна из самых интересных вещей — это разделы отчета, посвященные взаимодействию и корреляции. В разделе взаимодействия библиотека pandas_profiling автоматически генерирует графики взаимодействия для каждой пары переменных. Вы можете получить график взаимодействия любой пары, выбрав конкретные переменные из двух заголовков (как и в этом примере, я выбрал имя пассажира и возраст).

Матрица корреляции:
Корреляция — это статистический метод, который может показать, насколько сильно связаны пары переменных. Например, рост и вес связаны; высокие люди обычно тяжелее, чем люди ниже ростом. Отношения не идеальны. Люди одного роста различаются по весу, и вы можете легко представить себе двух знакомых, у которых более короткий тяжелее более высокого. Тем не менее, средний вес людей 5 футов 5 дюймов меньше, чем средний вес людей 5 футов 6 дюймов, а их средний вес меньше, чем у людей 5 футов 7 дюймов и т. Д. Корреляция может сказать вам, как Большая часть различий в весе людей связана с их ростом.
Главный результат корреляции называется коэффициентом корреляции (или «r»). Он колеблется от -1,0 до +1,0. Чем ближе r к +1 или -1, тем теснее связаны две переменные.
Если r близко к 0, это означает, что между переменными нет связи. Если r положительно, это означает, что по мере того, как одна переменная становится больше, другая становится больше. Если r отрицательно, это означает, что по мере того, как один становится больше, другой становится меньше (часто это называется «обратной» корреляцией).
Когда дело доходит до создания корреляционной матрицы для всех числовых характеристик, библиотека pandas_profiling дает нам на выбор все популярные варианты, включая Пирсона r, Спирмена ρ и т. Д.

Теперь, когда мы знаем преимущества использования pandas_profiling, полезно также отметить недостаток, который имеет эта библиотека.
Недостаток:
Основным недостатком профилирования pandas является его использование с большими наборами данных. С увеличением размера данных время создания отчета также значительно увеличивается.
Один из способов решить эту проблему — создать отчет о профиле для части набора данных. Но при этом очень важно убедиться, что данные выбираются случайным образом, чтобы они были репрезентативными для всех данных, которые у нас есть. Мы можем сделать это:
from pandas_profiling import ProfileReport # Generate report for 10000 data points profile = ProfileReport(data.sample(n = 10000), title=»Titanic Data set», html=>, sort=»None») # save to file profile.to_file(output_file=’10000datapoints.html’)
В качестве альтернативы, если вы настаиваете на получении отчета по всему набору данных, вы можете сделать это, используя минимальный режим. В минимальном режиме будет сгенерирован упрощенный отчет с меньшим количеством информации, чем полный, но он может быть сгенерирован относительно быстро для большого набора данных. Код для этого приведен ниже:
profile = ProfileReport(large_dataset, minimal=True) profile.to_file(output_file=»output.html»)
Заключение:
Теперь, когда вы знаете, что такое профилирование панд и как его использовать, я надеюсь, что это сэкономит вам массу времени, которое вы сможете использовать для более сложного анализа, специфичного для данной проблемы.
Если вы хотите получить полный отчет с рабочим кодом, вы можете взглянуть на следующую записную книжку. А если вы хотите прочитать другие мои статьи, вы можете найти ссылки ниже.
Репозиторий Pandas-Profiling на GitHub:
Если вам понравилась эта статья, возможно, вам понравятся некоторые из моих других статей.
Источник: digitrain.ru
Civil 3D 2017. Как к поверхности добавить объект профилирования?
Здравствуйте.
Создал поверхность по объектам профилирования. Меню «Главная» — «Поверхности» — «Создать поверхность на основе профилирования». Поверхность построилась.
Забыл рассчитать один откос. Рассчитал, с добавлением в ту же группу объектов профилирования.
Перерассчет поверхности не добавляет последний откос в нее.
Вопрос: как можно добавить в построенную поверхность объект профилирования?
Спасибо за помощь!
Просмотров: 3094
Регистрация: 24.03.2005
Сообщений: 319
А что команда _AeccEditSurfacePaste не помогает
Регистрация: 31.07.2011
Сообщений: 185
Имеется ввиду то, что на основе объекта профилирования создаем отдельную поверхность и врезаем её в корректируемую поверхность?
Регистрация: 24.03.2005
Сообщений: 319
да. и вы сами решайте что что во что врезать. какая поверхность у вас приоритетней
Регистрация: 31.07.2011
Сообщений: 185
Интересное решение! Спасибо!
Регистрация: 11.07.2017
Сообщений: 1

Как я могу это сделать? Autocad civil3d profile 3d kilometer например
Источник: forum.dwg.ru
Профилирование создания майнкрафт что это

Судовая карта
- Судовая карта (Travels)
- Экстремальная кулинария (Extreme cooking)
- Мастерская (Workshop)
- Видео (Movies)
- О блоге (About blog)
среда, 16 апреля 2014 г.
Уроки Civil 3d. Тонкости профилирования (создания откосов). Откосы с различными уклонами на одной характерной линии
Снова в рамках уроков в Civil 3d поговорим о профилировании (создании откосов). На сей раз рассмотрим профилирование с разными уклонами от одной характерной линии.
ВАЖНОЕ ЗАМЕЧАНИЕ! Для корректного моделирования настоятельно рекомендую ознакомиться со статьей по грамотному созданию чертежа с использованием шаблона Civil 3d. Если вы начнете работу с файлом, созданным без нормального шаблона, в дальнейшем почит наверняка будут косяки с настройками критериев профилирования и прочего. Вы застопоритесь и будете не понимать в чем проблема. Лучше потратьте 5 минут и сделайте нормальный чертеж.
Начнем с того, что создадим наборы критериев профилирования с необходимыми нам проекциями выемкинасыпи. Я создал 30, 18, и 23 градуса. Это будет у нас соответственно 1:1.71, 1:2.36 и 1:3.08 (из градусов в проекции можно пересчитать по формуле 1tgx, где x — это градусы).
Далее по известной нам схеме идем на вкладку ГлавнаяОбъект профилированияИнструменты профилирования. Затем определяем группу профилирования и создаем соответствующую поверхность. Опять-таки, не забываем при создании группы профилирования смотреть к какой площадке у нас она будет относиться (надо следить, чтобы площадка была та же, что и у характерной линии, от которой мы будем строить откосы — по умолчанию обычно она Site 1).
Выставляем необходимый критерий профилирования для откоса с первым уклоном (я выставил первым уклон 30 градусов). Жмем на «Создать объект профилирования». Выбираем характерную линию и выбираем сторону профилирования.

На сей раз мы на вопрос Цивила «применить ко всей длине?» отвечаем «Нет». Появится особая стрелочка, которой мы выбираем начало участка (первый клик — выбор точки, второй клик — назначение пикета) и конец участка.
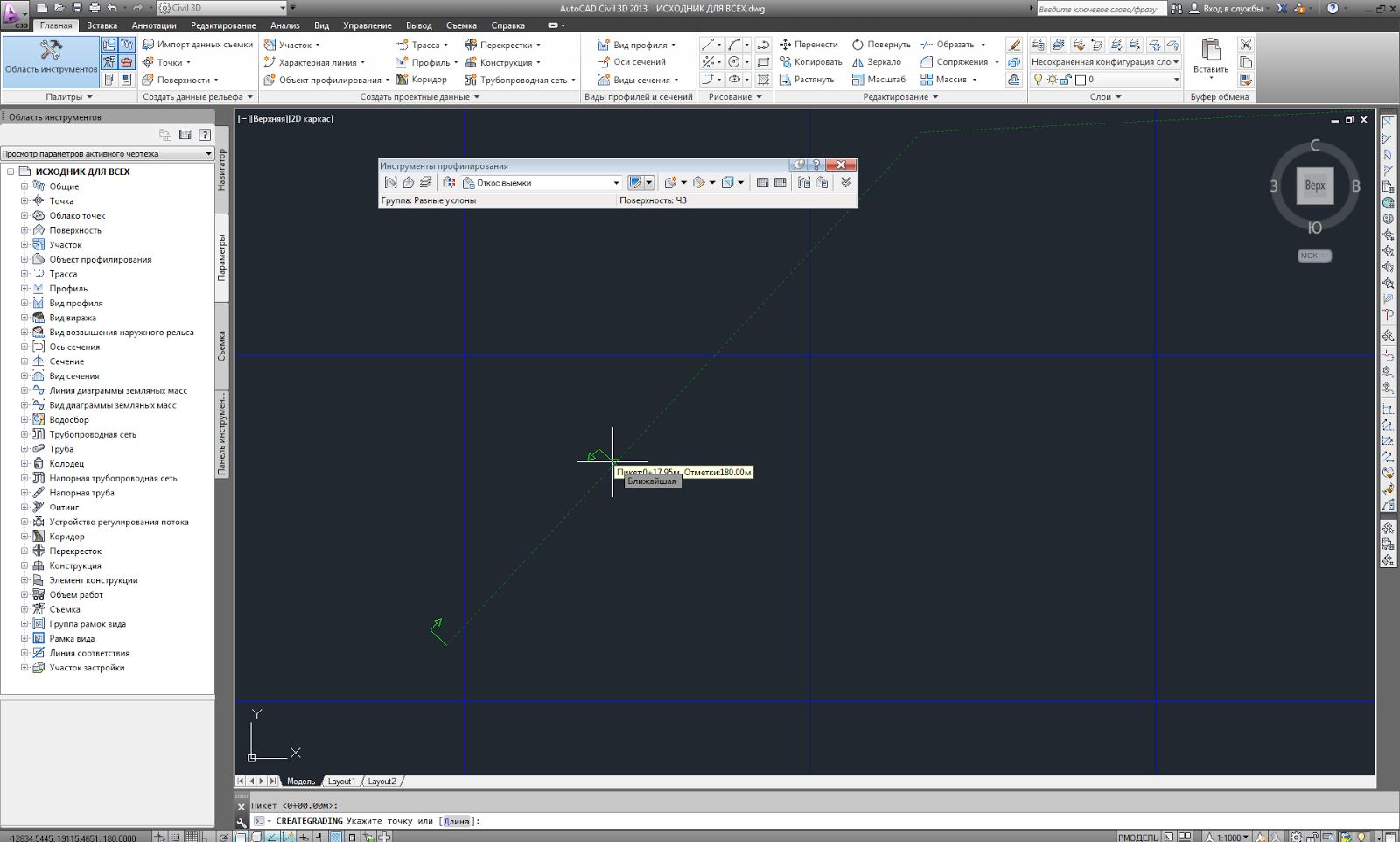
Подтверждаем проекцию выемкинасыпи. Теперь на этом участке построился откос с уклоном 30 градусов.
Далее мы размечаем для себя длину перехода между двумя разными уклонами откосов (я сделал 2 м).
Строим аналогично первому второй откос с другим уклоном (у меня 23 градуса).

Когда мы имеем рядом два участка откосов с разными уклонами, то мы можем создать между ними переход. Для этого мы выбираем команду «Создать переход»

Civil вопрошает: «Выберите объект!» Не вопрос — выбираем характерную линию, от которой строились наши участки откосов. Затем он просит тыкнуть в пространство между двумя участками откоса. Тыкаем. Он строит объект профилирования. Затем нажимаем Esc и происходит создание поверхности по объекту профилирования.
Вуаля — переход создан.

Таким же макаром делаем сколько захотим участков откосов с разными уклонами и переходов между ними.

Вот как-то так.
Имейте в виду следующее. Когда откосов и переходов в пределах одной характерной линии в чертеже наберется слишком много, обязательно начнутся проблемы, выражающиеся в Fatal Error, глюках — будут неправильные построения и выбросы, старые объекты профилирования будут «недружелюбно» реагировать на новопостроенные (трансформироваться в черти что). В следующем уроке Civil 3d я расскажу как обойти эту проблему.
Кстати существует еще один способ создать переходы между откосами — довольно варварский, но действенный (навроде как лечить простуду чистым спиртом). Об особенностях этого способа я также расскажу в очередном уроке Civil 3d.
Источник: www.aveursus.ru