Sequence-to-sequence модели (seq2seq) – это модели глубокого обучения, достигшие больших успехов в таких задачах, как машинный перевод, суммаризация текста, аннотация изображений и др. Так, например, в конце 2016 года подобная модель была встроена в Google Translate. Основы же seq2seq моделей были заложены еще в 2014 году с выходом двух статей — Sutskever et al., 2014, Cho et al., 2014.
Чтобы в достаточной мере понять и затем использовать эти модели, необходимо сначала прояснить некоторые понятия. Предложенные в данной статье визуализации будут хорошим дополнением к статьям, упомянутым выше.
Sequence-to-sequence модель – это модель, принимающая на вход последовательность элементов (слов, букв, признаков изображения и т.д.) и возвращающая другую последовательность элементов. Обученная модель работает следующим образом:
Your browser does not support HTML5 video.
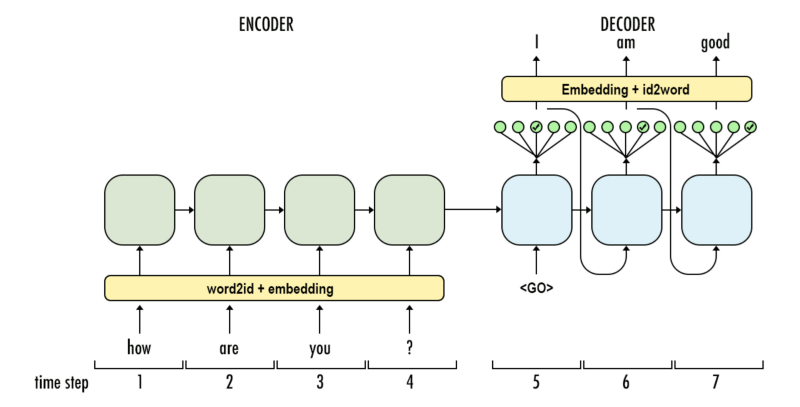
В нейронном машинном переводе, последовательность элементов – это набор слов, обрабатываемых поочередно. Выводом также является набор слов:
Your browser does not support HTML5 video.
Заглянем под капот
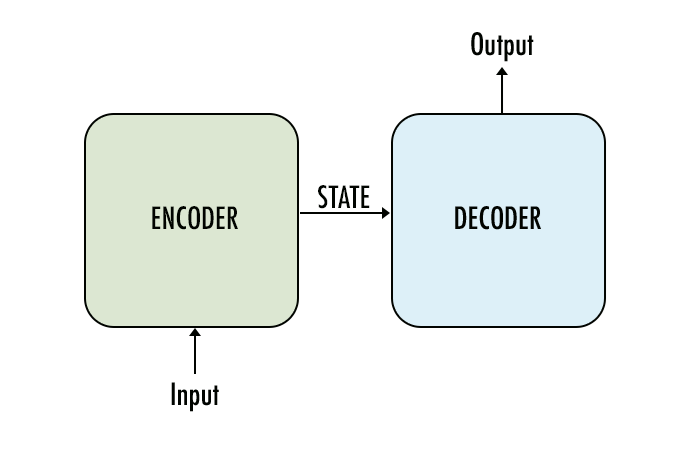
Под капотом у модели находятся энкодер и декодер.
Энкодер обрабатывает каждый элемент входной последовательности, переводит полученную информацию в вектор, называемый контекстом (context). После обработки всей входной последовательности энкодер пересылает контекст декодеру, который затем начинает генерировать выходную последовательность элемент за элементом.
Your browser does not support HTML5 video.
То же самое происходит и в случае машинного перевода.
Your browser does not support HTML5 video.
Применительно к машинному переводу контекст представляет собой вектор (массив чисел), а энкодер и декодер, в свою очередь, чаще всего являются рекуррентными нейронными сетями (см. введение в RNN — A friendly introduction to Recurrent Neural Networks).

Контекст – это вектор чисел с плавающей точкой. Далее в статье векторы будут визуализированы в цвете таким образом, что более светлый цвет соответствует ячейкам с большими значениями.
При обучении модели можно задать размер контекстного вектора – число скрытых нейронов (hidden units) в энкодере RNN. Данные визуализации показывают 4-мерный вектор, но в реальных приложениях контекстый вектор будет иметь размерность порядка 256, 512 или 1024.
По умолчанию в каждый временной отрезок RNN принимает на вход два элемента: непосредственно входной элемент (в случае энкодера, одно слово из исходного предложения) и скрытое состояние (hidden state). Слово, однако, должно быть представлено вектором. Для преобразования слова в вектор прибегают к ряду алгоритмов, называемых «эмбеддинги слов» (word embeddings). Эмбеддинги отображают слова в векторные пространства, содержащие смысловую и семантическую информацию о них (например, «король» – «мужчина» + «женщина» = «королева»).
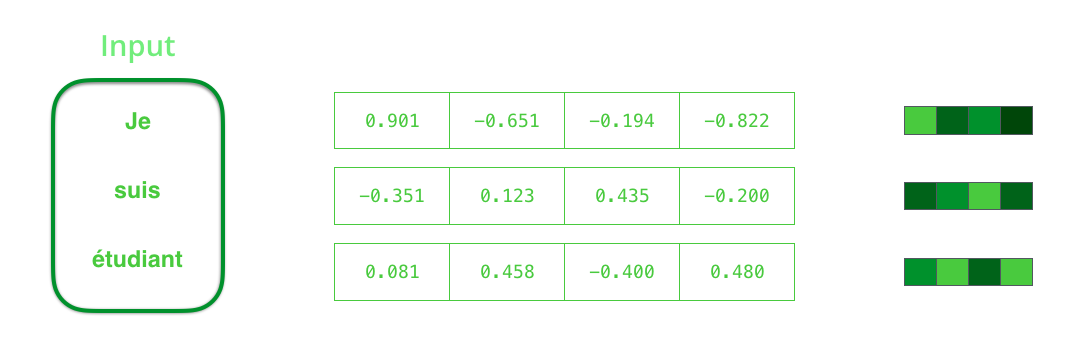
Прежде чем обрабатывать слова, необходимо преобразовать их в векторы. Эта трансформация осуществляется с помощью алгоритма эмбеддингов слов. Можно использовать как предобученные эмбеддинги, так и обучить эмбеддинги на своем наборе данных. 200-300 — типичная размерность вектора эмбеддинга; в данной статье для простоты используется размерность 4.
Теперь, когда мы познакомились с нашими основными векторами/тензорами, давайте вспомним механизм работы RNN и создадим визуализации для его описания:
Your browser does not support HTML5 video.
На следующем шаге RNN берет второй входной вектор и скрытое состояние #1 для формирования выхода на данном временном отрезке. Далее в статье подобная анимация используется для описания векторов внутри модели нейронного машинного перевода.
В следующей визуализации каждый кадр описывает обработку входов энкодером и генерацию выходов декодером за один временной отрезок. Так как и энкодер, и декодер представляют собой RNN, в каждый временной отрезок нейронная сеть занята обработкой и обновлением своих скрытых состояний на основе текущего и всех предыдущих входов. При этом последнее из скрытых состояний энкодера и является тем самым контекстом, который передается в декодер.
Your browser does not support HTML5 video.
Декодер также содержит скрытые состояния, которые он передает из одного временного отрезка в другой. (Этого нет в визуализации, изображающей лишь основные части модели.)
Обратимся теперь к другому виду визуализации sequence-to-sequence моделей. Эта анимация поможет понять статическую графику, которая описывает эти модели – т.н. развернутое (unrolled) представление, где вместо того, чтобы показывать один декодер, мы показываем его копию для каждого временного отрезка. Так мы можем посмотреть на входные и выходные элементы на каждом временном отрезке.
Your browser does not support HTML5 video.
Обратите внимание!
Контекстный вектор является бутылочным горлышком для такого типа моделей, благодаря чему, им сложно иметь дело с длинными предложениями. Решение было предложено в статьях Bahdanau et al., 2014 и Luong et al., 2015, где была представлена техника, получившая название «механизм внимания» (attention). Данный механизм значительно улучшает качество систем машинного перевода, позволяя моделям концентрироваться на релевантных частях входных последовательностей.
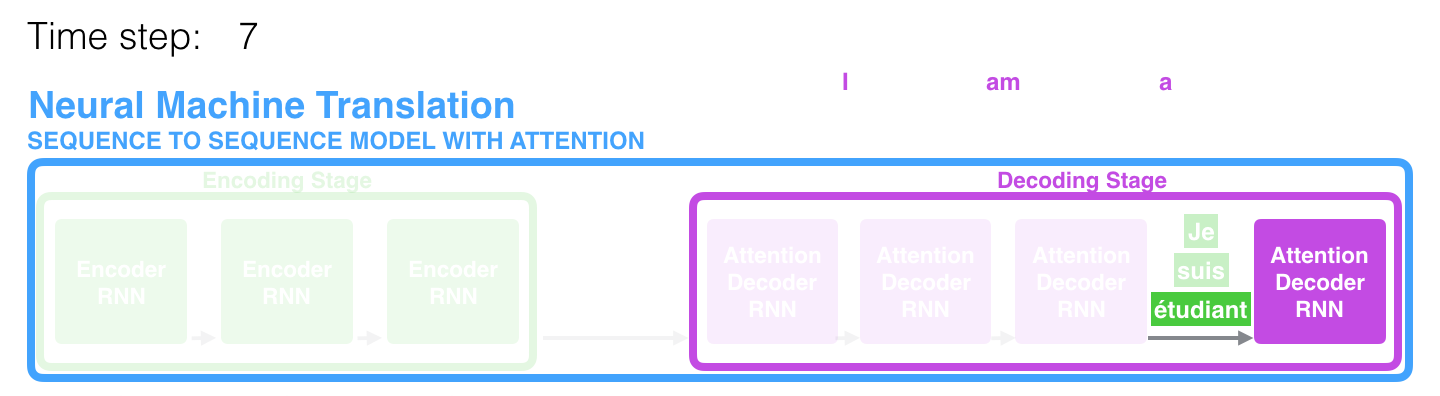
На 7-ом временном отрезке механизм внимания позволяет декодеру сфокусироваться на слове «étudiant» («student» по-французски), прежде чем сгенерировать перевод на английский. Эта способность усиливать сигнал от релевантной части входной последовательности позволяет моделям, основанным на механизме внимания, получать лучший результат по сравнению с остальными моделями.
При рассмотрении модели с механизмом внимания на высоком уровне абстракции можно выделить два основных отличия от классической sequence-to-sequence модели.
Во-первых, энкодер передает значительно больше данных декодеру: вместо передачи лишь последнего скрытого состояния после этапа кодирования, энкодер отправляет ему все свои скрытые состояния:
Your browser does not support HTML5 video.
Во-вторых, декодер проходит через дополнительный этап, прежде чем сгенерировать выход. Для того, чтобы сфокусироваться на тех частях входной последовательности, которые релевантны для соответствующего временного отрезка, декодер делает следующее:
- Смотрит на набор скрытых состояний, полученных от энкодера – каждое из скрытых состояний соотносится наилучшим образом с одним из слов в входной последовательности;
- Назначает каждому скрытому состоянию некую оценку (опустим пока, как происходит процедура оценивания);
- Умножает каждое скрытое состояние на преобразованную softmax функцией оценку, выделяя, таким образом, скрытые состояния с большой оценкой и отводя на второй план скрытые состояния с маленькой.
Your browser does not support HTML5 video.
Это «упражнение с оценками» производится в декодере на каждом временном отрезке.
Итак, подытоживая все вышеописанное, рассмотрим процесс работы модели с механизмом внимания:
- В декодере RNN получает эмбеддинг токена и первоначальное скрытое состояние.
- RNN обрабатывает входной элемент, генерирует выход и новый вектор скрытого состояния (h4). Выход отбрасывается.
- Механизм внимания использует скрытые состояния энкодера и вектор h4 для вычисления контекстного вектора (C4) на данном временном отрезке.
- Вектора h4 и C4 конкатенируются в один вектор.
- Этот вектор пропускается через нейронную сеть прямого распространения (feedforward neural network, FFN), обучаемую совместно с моделью.
- Вывод FFN сети указывает на выходное слово на данном временном отрезке.
- Алгоритм повторяется для следующего временного отрезка.
Your browser does not support HTML5 video.
Другой способ посмотреть на то, на какой части исходного предложения фокусируется модель на каждом этапе работы декодера:
Your browser does not support HTML5 video.
Обратите внимание, что модель не просто бездумно связывает первое слово на входе с первым словом на выходе. Она на самом деле поняла в процессе обучения, как сопоставлять слова в этой рассматриваемой языковой паре (в нашем случае — французский и английский). Пример того, насколько точно этот механизм может работать, можно посмотреть в статьях о механизме внимания, указанных выше.

Если вы чувствуете, что готовы научиться применять эту модель, обратитесь к руководству Neural Machine Translation (seq2seq) на TensorFlow.
Авторы
- Автор оригинала — Jay Alammar
- Перевод — Смирнова Екатерина
- Редактирование и вёрстка — Шкарин Сергей
Источник: habr.com
10) Модель seq2seq
NLP или Natural Language Processing – одна из популярных ветвей искусственного интеллекта, которая помогает компьютерам понимать, манипулировать или реагировать на человека на его естественном языке. НЛП – это движок Google Translate, который помогает нам понимать другие языки.
Что такое Seq2Seq?
Seq2Seq – это метод машинного перевода на основе кодера-декодера, который отображает ввод последовательности на вывод последовательности с тегом и значением внимания. Идея состоит в том, чтобы использовать 2 RNN, которые будут работать вместе со специальным токеном и пытаться предсказать следующую последовательность состояний из предыдущей последовательности.
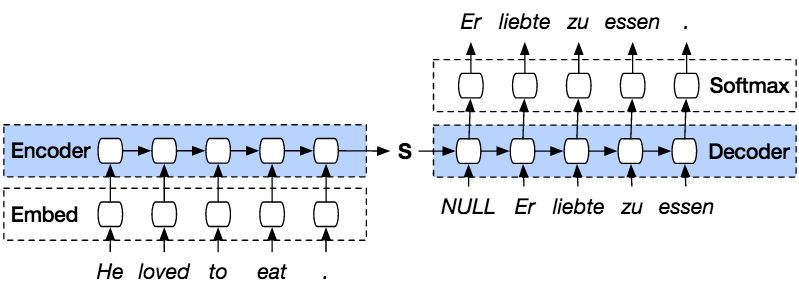
Шаг 1) Загрузка наших данных
Для нашего набора данных вы будете использовать набор данных из пар двуязычных предложений с разделителями табуляцией . Здесь я буду использовать англо-индонезийский набор данных. Вы можете выбрать что угодно, но не забудьте изменить имя файла и каталог в коде.
from __future__ import unicode_literals, print_function, division import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F import numpy as np import pandas as pd import os import re import random device = torch.device(«cuda» if torch.cuda.is_available() else «cpu»)
Шаг 2) Подготовка данных
Вы не можете использовать набор данных напрямую. Вам нужно разбить предложения на слова и преобразовать их в One-Hot Vector. Каждое слово будет уникально проиндексировано в классе Lang для создания словаря. Класс Lang будет хранить каждое предложение и разбивать его слово за словом с помощью addSentence. Затем создайте словарь, проиндексировав каждое неизвестное слово.
SOS_token = 0 EOS_token = 1 MAX_LENGTH = 20 #initialize Lang Class class Lang: def __init__(self): #initialize containers to hold the words and corresponding index self.word2index = <> self.word2count = <> self.index2word = self.n_words = 2 # Count SOS and EOS #split a sentence into words and add it to the container def addSentence(self, sentence): for word in sentence.split(‘ ‘): self.addWord(word) #If the word is not in the container, the word will be added to it, #else, update the word counter def addWord(self, word): if word not in self.word2index: self.word2index[word] = self.n_words self.word2count[word] = 1 self.index2word[self.n_words] = word self.n_words += 1 else: self.word2count[word] += 1
Класс Lang – это класс, который поможет нам создать словарь. Для каждого языка каждое предложение будет разбито на слова, а затем добавлено в контейнер. Каждый контейнер будет хранить слова в соответствующем индексе, подсчитывать слово и добавлять индекс слова, чтобы мы могли использовать его для нахождения индекса слова или нахождения слова по его индексу.
Поскольку наши данные разделены TAB, вам нужно использовать панд в качестве нашего загрузчика данных. Панды будут читать наши данные как dataFrame и разбивать их на наше исходное и целевое предложение. Для каждого предложения, которое у вас есть,
- вы нормализуете его в нижний регистр,
- удалить все не персонажа
- конвертировать в ASCII из Unicode
- разделите предложения, чтобы в них было каждое слово.
#Normalize every sentence def normalize_sentence(df, lang): sentence = df[lang].str.lower() sentence = sentence.str.replace(‘[^A-Za-zs]+’, ») sentence = sentence.str.normalize(‘NFD’) sentence = sentence.str.encode(‘ascii’, errors=’ignore’).str.decode(‘utf-8′) return sentence def read_sentence(df, lang1, lang2): sentence1 = normalize_sentence(df, lang1) sentence2 = normalize_sentence(df, lang2) return sentence1, sentence2 def read_file(loc, lang1, lang2): df = pd.read_csv(loc, delimiter=’t’, header=None, names=[lang1, lang2]) return df def process_data(lang1,lang2): df = read_file(‘text/%s-%s.txt’ % (lang1, lang2), lang1, lang2) print(«Read %s sentence pairs» % len(df)) sentence1, sentence2 = read_sentence(df, lang1, lang2) source = Lang() target = Lang() pairs = [] for i in range(len(df)): if len(sentence1[i].split(‘ ‘)) < MAX_LENGTH and len(sentence2[i].split(‘ ‘)) < MAX_LENGTH: full = [sentence1[i], sentence2[i]] source.addSentence(sentence1[i]) target.addSentence(sentence2[i]) pairs.append(full) return source, target, pairs
Еще одна полезная функция, которую вы будете использовать, – конвертация пар в Tensor. Это очень важно, потому что наша сеть читает только данные тензорного типа. Это также важно, потому что это та часть, в которой на каждом конце предложения будет присутствовать токен, сообщающий сети, что ввод завершен. Для каждого слова в предложении он получит индекс из соответствующего слова в словаре и добавит маркер в конце предложения.
def indexesFromSentence(lang, sentence): return [lang.word2index[word] for word in sentence.split(‘ ‘)] def tensorFromSentence(lang, sentence): indexes = indexesFromSentence(lang, sentence) indexes.append(EOS_token) return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1) def tensorsFromPair(input_lang, output_lang, pair): input_tensor = tensorFromSentence(input_lang, pair[0]) target_tensor = tensorFromSentence(output_lang, pair[1]) return (input_tensor, target_tensor)
Модель Seq2Seq
Модель Seq2Seq – это разновидность модели, которая использует Encoder и Decoder поверх модели. Кодировщик закодирует слово предложения по словам в индексированный словарь или известные слова с индексом, а декодер будет прогнозировать выход кодированного ввода путем последовательного декодирования ввода и попытается использовать последний ввод в качестве следующего ввода, если возможно.
С помощью этого метода также можно предсказать следующий вход для создания предложения. Каждому предложению будет присвоен токен для обозначения конца последовательности. В конце прогноза также будет маркер, обозначающий конец вывода. Таким образом, от кодера он передает состояние декодеру для прогнозирования вывода.
Кодировщик будет последовательно кодировать наше входное предложение слово за словом, и в конце будет маркер, обозначающий конец предложения. Кодер состоит из уровня Embedded и уровней GRU. Слой Embedding – это таблица соответствия, в которой хранится наш ввод в словарь фиксированного размера. Он будет передан в слой GRU.
Слой GRU представляет собой Gated Recurrent Unit, который состоит из нескольких типов RNN, которые будут рассчитывать последовательный ввод. Этот слой будет рассчитывать скрытое состояние из предыдущего и обновлять сброс, обновление и новые ворота.
Декодер декодирует вход с выхода кодера. Он будет пытаться предсказать следующий вывод и попытаться использовать его как следующий, если это возможно. Декодер состоит из слоя внедрения, слоя GRU и линейного слоя. Уровень встраивания создаст таблицу поиска для вывода и будет передан в слой GRU для расчета прогнозируемого состояния вывода. После этого линейный слой поможет рассчитать функцию активации, чтобы определить истинное значение прогнозируемого выхода.
class Encoder(nn.Module): def __init__(self, input_dim, hidden_dim, embbed_dim, num_layers): super(Encoder, self).__init__() #set the encoder input dimesion , embbed dimesion, hidden dimesion, and number of layers self.input_dim = input_dim self.embbed_dim = embbed_dim self.hidden_dim = hidden_dim self.num_layers = num_layers #initialize the embedding layer with input and embbed dimention self.embedding = nn.Embedding(input_dim, self.embbed_dim) #intialize the GRU to take the input dimetion of embbed, and output dimention of hidden and #set the number of gru layers self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers) def forward(self, src): embedded = self.embedding(src).view(1,1,-1) outputs, hidden = self.gru(embedded) return outputs, hidden class Decoder(nn.Module): def __init__(self, output_dim, hidden_dim, embbed_dim, num_layers): super(Decoder, self).__init__() #set the encoder output dimension, embed dimension, hidden dimension, and number of layers self.embbed_dim = embbed_dim self.hidden_dim = hidden_dim self.output_dim = output_dim self.num_layers = num_layers # initialize every layer with the appropriate dimension. For the decoder layer, it will consist of an embedding, GRU, a Linear layer and a Log softmax activation function. self.embedding = nn.Embedding(output_dim, self.embbed_dim) self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers) self.out = nn.Linear(self.hidden_dim, output_dim) self.softmax = nn.LogSoftmax(dim=1) def forward(self, input, hidden): # reshape the input to (1, batch_size) input = input.view(1, -1) embedded = F.relu(self.embedding(input)) output, hidden = self.gru(embedded, hidden) prediction = self.softmax(self.out(output[0])) return prediction, hidden class Seq2Seq(nn.Module): def __init__(self, encoder, decoder, device, MAX_LENGTH=MAX_LENGTH): super().__init__() #initialize the encoder and decoder self.encoder = encoder self.decoder = decoder self.device = device def forward(self, source, target, teacher_forcing_ratio=0.5): input_length = source.size(0) #get the input length (number of words in sentence) batch_size = target.shape[1] target_length = target.shape[0] vocab_size = self.decoder.output_dim #initialize a variable to hold the predicted outputs outputs = torch.zeros(target_length, batch_size, vocab_size).to(self.device) #encode every word in a sentence for i in range(input_length): encoder_output, encoder_hidden = self.encoder(source[i]) #use the encoder’s hidden layer as the decoder hidden decoder_hidden = encoder_hidden.to(device) #add a token before the first predicted word decoder_input = torch.tensor([SOS_token], device=device) # SOS #topk is used to get the top K value over a list #predict the output word from the current target word. If we enable the teaching force, then the #next decoder input is the next word, else, use the decoder output highest value. for t in range(target_length): decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden) outputs[t] = decoder_output teacher_force = random.random() < teacher_forcing_ratio topv, topi = decoder_output.topk(1) input = (target[t] if teacher_force else topi) if(teacher_force == False and input.item() == EOS_token): break return outputs
Шаг 3) Обучение модели
Процесс обучения начинается с преобразования каждой пары предложений в тензоры из их индекса Ланга. Наша модель будет использовать SGD в качестве оптимизатора и функцию NLLLoss для расчета потерь. Процесс обучения начинается с подачи пары предложений в модель, чтобы предсказать правильный результат. На каждом шаге выходные данные модели будут рассчитываться с использованием истинных слов, чтобы найти потери и обновить параметры. Так как вы будете использовать 75000 итераций, наша модель будет генерировать случайные 75000 пар из нашего набора данных.
teacher_forcing_ratio = 0.5 def clacModel(model, input_tensor, target_tensor, model_optimizer, criterion): model_optimizer.zero_grad() input_length = input_tensor.size(0) loss = 0 epoch_loss = 0 # print(input_tensor.shape) output = model(input_tensor, target_tensor) num_iter = output.size(0) print(num_iter) #calculate the loss from a predicted sentence with the expected result for ot in range(num_iter): loss += criterion(output[ot], target_tensor[ot]) loss.backward() model_optimizer.step() epoch_loss = loss.item() / num_iter return epoch_loss def trainModel(model, source, target, pairs, num_iteration=20000): model.train() optimizer = optim.SGD(model.parameters(), lr=0.01) criterion = nn.NLLLoss() total_loss_iterations = 0 training_pairs = [tensorsFromPair(source, target, random.choice(pairs)) for i in range(num_iteration)] for iter in range(1, num_iteration+1): training_pair = training_pairs[iter — 1] input_tensor = training_pair[0] target_tensor = training_pair[1] loss = clacModel(model, input_tensor, target_tensor, optimizer, criterion) total_loss_iterations += loss if iter % 5000 == 0: avarage_loss= total_loss_iterations / 5000 total_loss_iterations = 0 print(‘%d %.4f’ % (iter, avarage_loss)) torch.save(model.state_dict(), ‘mytraining.pt’) return model
Шаг 4) Проверьте модель
Процесс оценки заключается в проверке выходных данных модели. Каждая пара предложений будет вводиться в модель и генерировать предсказанные слова. После этого вы будете искать самое высокое значение на каждом выходе, чтобы найти правильный индекс. И, наконец, вы сравните, чтобы увидеть наш прогноз модели с истинным предложением
def evaluate(model, input_lang, output_lang, sentences, max_length=MAX_LENGTH): with torch.no_grad(): input_tensor = tensorFromSentence(input_lang, sentences[0]) output_tensor = tensorFromSentence(output_lang, sentences[1]) decoded_words = [] output = model(input_tensor, output_tensor) # print(output_tensor) for ot in range(output.size(0)): topv, topi = output[ot].topk(1) # print(topi) if topi[0].item() == EOS_token: decoded_words.append(») break else: decoded_words.append(output_lang.index2word[topi[0].item()]) return decoded_words def evaluateRandomly(model, source, target, pairs, n=10): for i in range(n): pair = random.choice(pairs) print(‘source <>’.format(pair[0])) print(‘target <>’.format(pair[1])) output_words = evaluate(model, source, target, pair) output_sentence = ‘ ‘.join(output_words) print(‘predicted <>’.format(output_sentence))
Теперь давайте начнем наше обучение с количества итераций 75000 и числом RNN уровня 1 со скрытым размером 512.
lang1 = ‘eng’ lang2 = ‘ind’ source, target, pairs = process_data(lang1, lang2) randomize = random.choice(pairs) print(‘random sentence <>’.format(randomize)) #print number of words input_size = source.n_words output_size = target.n_words print(‘Input : <> Output : <>’.format(input_size, output_size)) embed_size = 256 hidden_size = 512 num_layers = 1 num_iteration = 100000 #create encoder-decoder model encoder = Encoder(input_size, hidden_size, embed_size, num_layers) decoder = Decoder(output_size, hidden_size, embed_size, num_layers) model = Seq2Seq(encoder, decoder, device).to(device) #print model print(encoder) print(decoder) model = trainModel(model, source, target, pairs, num_iteration) evaluateRandomly(model, source, target, pairs)
Как вы можете видеть, наше предсказанное предложение не очень хорошо соответствует, поэтому, чтобы получить более высокую точность, вам нужно тренироваться с большим количеством данных и попытаться добавить больше итераций и количество слоев.
random sentence [‘tom is finishing his work’, ‘tom sedang menyelesaikan pekerjaannya’] Input : 3551 Output : 4253 Encoder( (embedding): Embedding(3551, 256) (gru): GRU(256, 512) ) Decoder( (embedding): Embedding(4253, 256) (gru): GRU(256, 512) (out): Linear(in_features=512, out_features=4253, bias=True) (softmax): LogSoftmax() ) Seq2Seq( (encoder): Encoder( (embedding): Embedding(3551, 256) (gru): GRU(256, 512) ) (decoder): Decoder( (embedding): Embedding(4253, 256) (gru): GRU(256, 512) (out): Linear(in_features=512, out_features=4253, bias=True) (softmax): LogSoftmax() ) ) 5000 4.0906 10000 3.9129 15000 3.8171 20000 3.8369 25000 3.8199 30000 3.7957 35000 3.8037 40000 3.8098 45000 3.7530 50000 3.7119 55000 3.7263 60000 3.6933 65000 3.6840 70000 3.7058 75000 3.7044 > this is worth one million yen = ini senilai satu juta yen < tom sangat satu juta yen > she got good grades in english = dia mendapatkan nilai bagus dalam bahasa inggris < tom meminta nilai bagus dalam bahasa inggris > put in a little more sugar = tambahkan sedikit gula < tom tidak > are you a japanese student = apakah kamu siswa dari jepang < tom kamu memiliki yang jepang > i apologize for having to leave = saya meminta maaf karena harus pergi < tom tidak maaf karena harus pergi ke >he isnt here is he = dia tidak ada di sini kan < tom tidak > speaking about trips have you ever been to kobe = berbicara tentang wisata apa kau pernah ke kobe < tom tidak > tom bought me roses = tom membelikanku bunga mawar < tom tidak bunga mawar > no one was more surprised than tom = tidak ada seorangpun yang lebih terkejut dari tom < tom ada orang yang lebih terkejut > i thought it was true = aku kira itu benar adanya
Источник: coderlessons.com
Насилие сексуальное, групповое: SexLab Group Rape

Как еще можно опошлить мир скайрима? Казалось бы использованы все доступные инструменты. Тот же секс во всех мыслимых вариациях в него уже добавили. Теперь каждый второй Довакин либо фетишист, либо насильник, либо любитель носить под латами женские трусы. Ну, то такое.
Потаенные грезы – личное дело Довакина. Однако если свои пристрастия Довакин водружает аки флаг и начинает за собой вести толпу, это уже совсем другое дело. Гей-парады в Скайриме ? Нет, здесь кое-что похуже… Групповые изнасилования! Банды насильников, организованная секс-преступность..караул, спасите, помогите!
Если раньше изнасилования в Скайриме носили форму интимного действа, то теперь они напоминают публичную порку (кстати подходящее название). Мод добавляет в игру групповое насилие (до 16 участников со стороны “нападающих”, не исключено привлечение к подобному сексуальному приключению и спутниц женского пола). Мод позволяет настраивать механику и характер действий, как-то: доступность насилия в бою и в местах дислокации стражников, в военных лагерях, настройка последствий насилия, их уровня и продолжительности действия, установка иммунитета ГГ против насилияотсутствия оного, кроме того присутствуют некоторые настройки для сбора подельников-насильников (быстрое их перемещение к месту насилия и тп) Установка: Скопировать содержимое архива в папку skyrimdata, активировать в лаунчере Удаление: удалить ..DataScripts_DMF_ERalias.pex (..DataScriptsSource_DMF_ERalias.pcs) (если установлен) ТребованияSexlab
Framework 1.5+ .kno:hover
Источник: skyrim-5.ru